
Infrastructure teams face two critical problems with traditional source of truth and data management tools.
First, most schemas are too generic. They try to accommodate every possible use case so most fields end up being optional and validation becomes meaningless.
Second, most schemas are too rigid. They're locked deep in the database core, and often tightly coupled to the platform itself, so changes require heavy migrations and risk breaking everything downstream.
These challenges create real pain for infrastructure teams trying to build automation. You can't trust data that might be incomplete, and you can't adapt quickly when every schema change is a high-stakes operation.
The Infrahub schema is both well-defined and flexible. You get strict validation where you need it and the ability to evolve your schema alongside your infrastructure without breaking integrations.
Schemas in a nutshell
A schema defines how your data is organized. It specifies what types of objects exist, what attributes those objects have, and how they relate to each other.
The schema provides structure and integrity for your data. It enforces rules like "every device must have a name" or "an interface can only connect to one device." This enables validation, powers query engines, and helps you understand what data you have at any given time.
For more on schemas and how they work, see An Automation Engineer's Guide to Understanding Data Schemas.
The problem with generic schemas
When a schema tries to fit multiple use cases, data chaos generally ensues.
First, you'll have a lot fields you never use, but you'll also need to create a lot of custom fields for the data to be useful and relevant for your organization.
Second, when the schema tries to accommodate all the use cases, everything becomes optional. Take NetBox's device model as an example: the name field is optional. This rightly drives people crazy. How do you have a device without a name?
The schema becomes permissive to handle edge cases but you lose first-level validation.
The impact cascades through your automation. You can't trust that a device has a name so you write defensive code everywhere, checking for optional fields and edge cases. Your automation becomes brittle because the schema doesn't enforce the rules you actually need.
The problem with rigid schemas
Schemas in traditional source of truth tools are very hard to change for two reasons.
First, these tools are built on relational databases that store data in tables. When you make a schema change, you're modifying how data is fundamentally stored and queried in those tables, which makes the operation very intensive.
Second, in tools like NetBox and Nautobot, the schema is tightly coupled to the platform itself. That means you can't just modify a device model without potentially breaking the application and everything downstream, including plugins, APIs, and integrations that depend on the schema structure.
The combination of database constraints and tight architectural coupling makes schema evolution risky. Even small changes require careful planning and coordination.
Why flexible, well-defined schemas matter for automation
The combination of a schema that's both too generic and too rigid is particularly painful. You get a schema that doesn't validate what you need it to validate, and you can't update it without major operational risk.
Infrastructure doesn't stand still. Every new service, device type, or business requirement needs schema changes. If you can't extend your schema easily, you can't keep up with business demands.
But extension isn't enough. You also need schemas that are specific to your use cases. A router needs different mandatory fields than a patch panel, and a managed Wi-Fi service needs different attributes than a point-to-point circuit.
Service-level modeling makes this especially critical. If you're managing infrastructure as logical services rather than individual technical elements, you need custom schemas that reflect your business. No two organizations have identical service definitions, so flexibility isn't a luxury, it's a requirement.
Well-defined schemas are also critical for AI. Agents need clear, documented structures to understand and interact with your data. If every field is optional because the schema tries to serve 10 different scenarios, agents can't reason about what's required or what relationships actually mean.
You need a schema that's both flexible and well-defined.
How the schema works in Infrahub
In Infrahub, you define your schema as a YAML file. You describe the objects you want, their attributes, and the relationships between them.
Infrahub reads that schema and automatically generates the UI, API, and version control capabilities. You don't write additional code.
Every schema includes three components:
- Structure defines your object types and their attributes.
- Relationships specify how objects connect to each other (one-to-one, one-to-many, many-to-many).
- Constraints set validation rules, required fields, and referential integrity.
Infrahub enforces your constraints. If you define that a device must have a name, Infrahub won't let you create a device without one. If you specify that an interface can only belong to one device, Infrahub blocks adding the interface to a second device. You get proper business logic enforcement.
But the schema isn't locked in the database core. Infrahub is built on a graph database, where the schema is decoupled from the platform. This means you can update the schema at any time without heavy migration operations or application restarts.
More importantly, Infrahub exposes artifacts (prepared configuration files, JSON payloads, Terraform configs) to your automation stack rather than raw schema data. This decoupling means integrated tools don't break when you evolve your schema.
Infrahub uses polymorphism to enable well-defined schemas
Polymorphism sounds complex but the idea is simple, and it solves a practical problem you've probably encountered many times: objects in the same category aren't always identical.
In many source of truth platforms, there's a generic "device" object that represents routers, switches, firewalls, patch panels, and servers all at once. The data model has to accommodate everything so most fields end up being optional.
But a router should have a management IP address and a patch panel shouldn't. If the model treats them both as generic devices, there's no way to enforce that rule. Unless you use polymorphism, like Infrahub does.
Polymorphism lets you define a base type (like Device), then create specialized types that inherit from it (like Router or PatchPanel). Each specialized type can have its own mandatory fields and relationships while still maintaining a simple relationship from other objects.
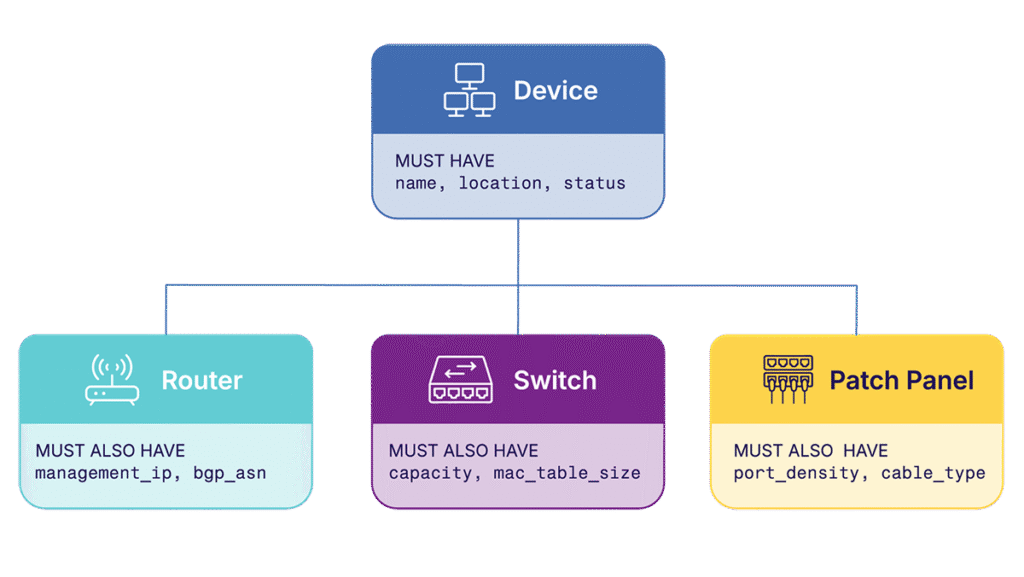
Polymorphism makes your data model more accurate and your automation more reliable. Instead of writing defensive code that checks whether optional fields exist, you define what's mandatory for each type. The schema enforces your business logic.
This is particularly important for design-driven automation, where you're modeling high-level services and business intent rather than just low-level configuration details. Different service types need different attributes, and polymorphism gives you a clean way to handle that.
Infrahub's graph database enables schema flexibility
Infrahub is built on a graph database. This choice of database matters more than you might think for the schema.
Relational databases like Postgres or MySQL organize data in tables. The schema is defined at the heart of the database, in what you might call kernel space if you're borrowing from Linux terminology. This creates rigidity since any schema changes modify the core structure of the data model.
Graph databases don't use tables. Instead, they use a much more flexible model where new objects and relationships can be added without changing anything about the existing data. The schema exists and it's enforced but it lives in user space rather than being baked into the database core.
For Infrahub, this architectural choice is fundamental. If the goal is having a schema that can evolve alongside your infrastructure, a relational database works against you. A graph database gives you the flexibility you need to extend or evolve your schema without sacrificing the validation that ensures data integrity.
Infrahub's version-controlled schemas allow safe collaboration
Version control isn't just for configuration files! It's for your entire infrastructure state, including the schema that defines how that state is structured. In Infrahub, schemas can be different on every branch.
Want to add a new device type with specific attributes? In a traditional system, you'd need to plan the change carefully, coordinate with everyone using the database, and hope you didn't break anything when you applied it to production.
In Infrahub, you simply create a branch. You modify the schema in that branch. You test it, validate it, make sure everything works as expected. When you're ready, you open a proposed change to merge your schema modifications into the main branch.
Infrahub applies the necessary migrations in your branch first. When you merge, those same migrations are applied to main. If something goes wrong, your production instance is never affected because the changes stay isolated in the branch.
This removes fear from schema evolution. Schema modifications become routine rather than high-stakes operations. It also means you can model just your core objects for a quick start, then easily add more over time.
Infrahub schema FAQs
Do I need to define the schema for my entire infrastructure to get started?
Is defining a schema in Infrahub a complex task?
Do I have to start from scratch in defining my schema?
What's the relationship between schema and GraphQL in Infrahub?
How does Infrahub enforce schema constraints?
This happens at the API level, the UI level, and internally within Infrahub. There's no way to bypass schema validation. This is how Infrahub maintains data integrity even as schemas evolve.
Can I import or migrate schemas from other tools?
Ready to build with the Infrahub schema?
If you're ready to explore how the Infrahub schema can help solve your infrastructure data management challenges, here are some next steps:
- Get detailed guidance on defining schemas, working with polymorphism, and managing schema evolution in the Infrahub documentation
- Experiment with example schemas and see how Infrahub auto-generates UI and API capabilities in the Infrahub sandbox.
- Get a walkthrough of the Infrahub schema in our technical livestream recording.
- Talk with the OpsMill team about your specific use cases and schema requirements by booking a demo.
