
Building a new AI data center is expensive, time-sensitive, and fraught with pressure.
Consider that AI data centers are often gigantic. They typically contain thousands of networking devices, tens of thousands of servers, hundreds of thousands of ports and cables, and perhaps millions of layered, hierarchical, and service data relationships across compute, network, and storage systems.
The level of detail and the size of the challenge to automate it all is seriously non-trivial.
I was part of the OpsMill team that recently helped build out the automation for a greenfield AI data center, taking the project from initial design to Day 2 operations to hit a tight six-month deadline.

From that experience, our team pulled out eight lessons about data center automation that proved effective in moving the project quickly and accurately despite the complexity.
1. Design for automation before you design the network
It feels intuitive that on a greenfield site, you'd design the network first and automate later. But for large-scale AI data center deployments, that's the wrong order.
The more standardized your physical topology (rack types, pod patterns, spine-leaf ratios and the like), the more work your automation can handle without human intervention.
This principle goes by many names but the framing that captures it best is cattle, not pets. When every pod is identical to every other pod, you can automate the build once and apply it everywhere.
2. Model only what you need, when you need it
One of the most common failure modes in automation projects is over-modeling. Teams try to capture everything in the schema before they've built anything, and the weight of that complexity slows them down before they've shipped a single deliverable.
The better approach: define the minimum schema required to produce your next artifact, ship that, and add to the schema as requirements become clear.
Adding attributes is easy. Untangling a complex, deeply nested schema that isn't serving you is painful, and it burns time you don't have.
3. Decouple the physical and the logical
Physical cabling and logical network configuration are related problems, but they're not the same problem. Building them as a single monolithic automation process means any change to one layer forces you to regenerate the other.
Separating them into independent processes gives you the flexibility to iterate on the logical layer—such as updating BGP sessions or tweaking VLAN assignments—without re-running the physical build.
On a project with hundreds of racks and thousands of cables, that separation is what keeps iteration times manageable. A design error in the overlay gets fixed without shipping a new cabling plan to the DC team.
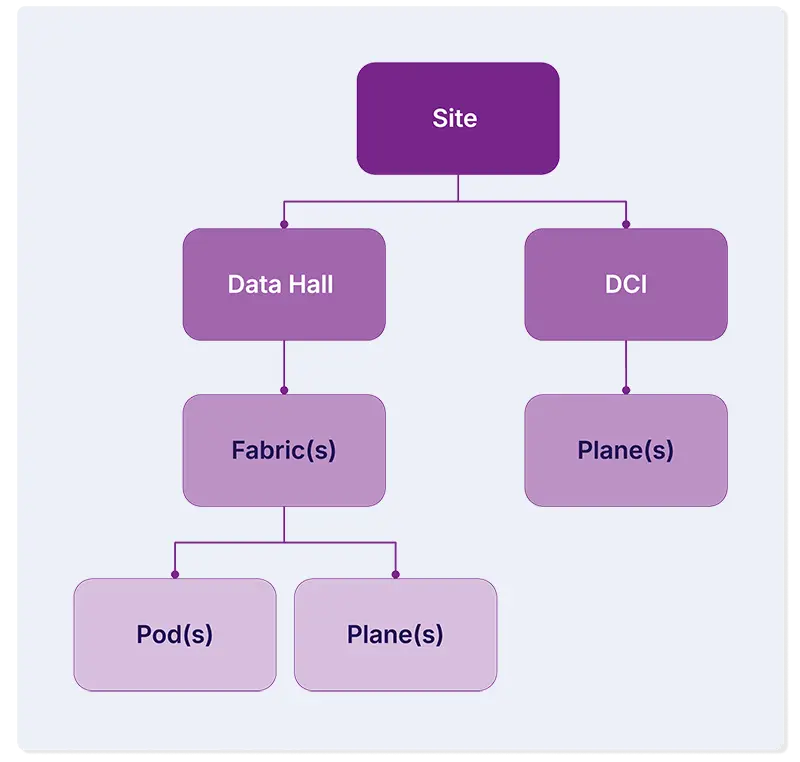
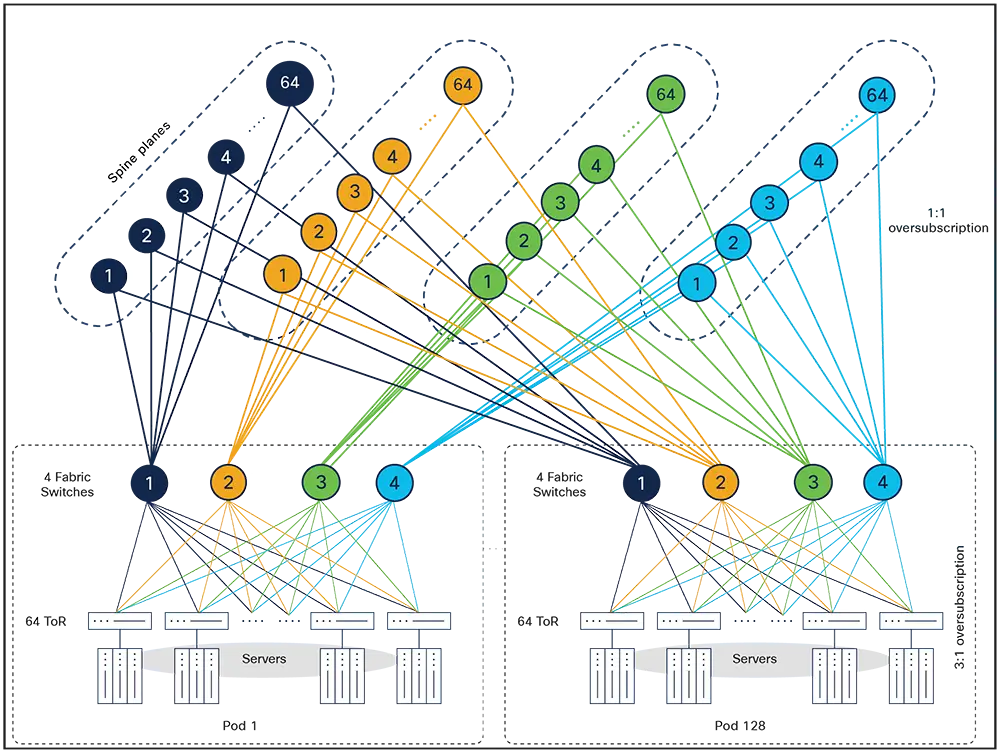
4. Build scalability through composable building blocks
A data center is not one thing but a hierarchy of things. Buildings contain rooms, rooms contain halls, halls contain racks, racks contain devices. Fabrics are built from pods. Pods contain spines and leaves.
Automation that models this hierarchy as a flat structure will fight you at every turn. Automation that mirrors the composable nature of the physical design can scale at each level independently.
Need to add a spine plane to support pod growth? That should be a targeted operation, not a full regeneration of the entire fabric. Keep your automation units small enough to target a single pod, and you can iterate on Pod 1 while Pods 2 through 100 stay untouched.
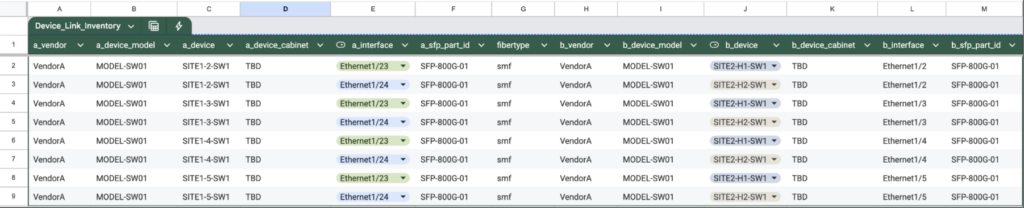
5. Create tangible outputs early
Automation teams lose stakeholder trust fast when the work is invisible. A database full of correctly modeled objects is meaningful to an automation engineer. To a network architect or a DC deployment team, it's not as clear.
Generating human-readable outputs early—cable plans as CSVs, device configs in familiar formats—creates a feedback loop that catches mistakes before equipment gets racked.
Show stakeholders something they can review, and you'll surface data quality issues in days rather than discovering them when the DC team is standing in front of a rack with a cable in hand.
Generate those artifacts continuously, not just at project milestones, and everyone stays aligned throughout.
6. Write automation that manages its own state
Automation that requires humans to carefully track what it last did is fragile automation. The goal is automation that knows what it built, can identify the difference between what it intended and what currently exists, and can reconcile those two things on its own.
That means writing automation that's idempotent and declarative. Run the same process twice and you get the same result. Remove an input and the automation removes the corresponding objects. No orphaned configurations, no manual cleanup, no drift accumulating over time.
In a large-scale data center automation project, this property is what keeps the system trustworthy as the operation grows and changes pile up.
7. Day 0 and Day 2 are the same problem
A lot of teams build their Day 0 automation, ship the data center, and then discover that every Day 2 workflow—adding VLANs, extending pods, replacing racks—requires writing automation from scratch against a data model they barely remember.
The better approach is to build Day 2 alongside Day 0, using the same underlying libraries and business logic.
Adding a rack on Day 2 should invoke the same code that built racks on Day 0. When it does, you get updated cabling plans, refreshed device configs, and accurate service models without additional work. The output of your Day 2 workflow becomes a diff, not a new project.
8. Treat network intent like code
The most mature signal in a data center automation project is how changes get managed. Not whether they're automated but whether they're proposed, reviewed, and applied through a consistent process, the same way software changes are.
When a fabric ASN changes, that change should happen in one place and propagate everywhere. When an engineer adds a service, they should create a branch, define the intent, open a proposed change, and watch the pipeline validate it before anything touches the network.
That's good process hygiene that helps makes automation trustworthy at scale. It gives the whole team confidence that the source of truth is actually true.
The common thread
These eight lessons reinforce each other. Standardized design makes it possible to start lean. Decoupling layers makes modularity practical. Tangible outputs keep the feedback loop tight. Idempotent automation makes Day 2 reuse safe. And managing intent like code ties all of it together into something the whole team can trust.
Data center automation at this scale is genuinely hard. The teams that succeed are the ones who treat it as a software engineering problem from the start rather than a one-time configuration push at launch.
Dig deeper
- Watch the full webinar on automating an AI data center to hear insights directly from the Solutions Architects who worked on the project.
- Explore data center automation, hands-on. Our DC bundle lets you spin up a working data center automation environment and drive it yourself.
- Book time with our team to discuss your data center project and how Infrahub can help.
