
You've defined your schema. Now where do you actually store your data?
In our companion article on schemas, we explored how schemas define the structure, relationships, and constraints of your data. But a schema is just the blueprint. To actually build a network source of truth or any automation system, you need somewhere to store that data—and that's where databases come in.
If you're stepping into network automation, understanding databases is a key skill. The database you choose shapes what's possible in your automation, how fast your queries run, how easily you can evolve your data model, and ultimately whether your system scales or collapses under real-world complexity.
There are always trade-offs
To start, be aware that there's no perfect database. (Just like we said in our post on schemas, there's no perfect schema either.)
Different database types optimize for very different things so the one you want to use will depend entirely on your use case. Common trade-offs include:
- Speed vs. integrity: Some databases sacrifice data consistency checks to achieve blazing fast performance.
- Flexibility vs. consistency: Some databases make schema changes trivial but give you less guarantee your data is valid.
- Scalability vs. query complexity: Some databases scale to billions of records but limit how complex your queries can be.
The 5 major database categories
Let's explore the major database categories and what each one brings to the table.
1. Relational databases (SQL)
When most people say "database," they mean a relational database. These are the PostgreSQL, MySQL, and Oracle systems that have dominated the landscape since the 1970s.
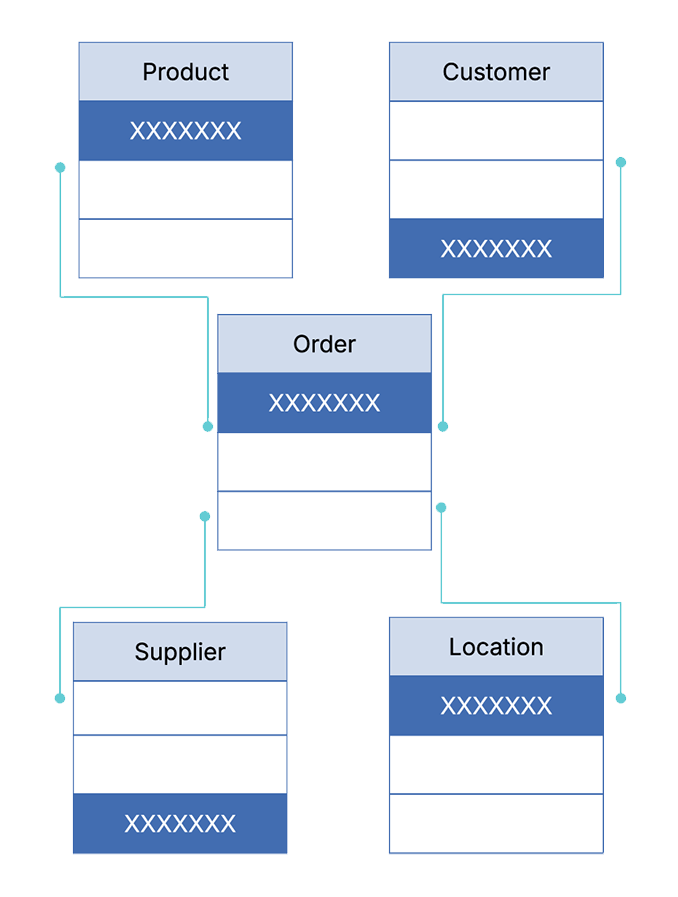
How they work: Relational databases organize data into tables. Each type of object gets its own table, and each instance of that object becomes a row in the table.
Columns represent attributes. Relationships between objects are managed through foreign keys, which are columns that reference the primary key of another table.
Strengths of relational databases:
- Mandatory schema enforcement: The database won't let you violate your schema. If you say a device must have a name, you can't insert a device without one.
- ACID transactions: Your data is guaranteed to stay consistent even during complex operations.
- Powerful SQL query language: It's mature, standardized, and incredibly capable.
- Built-in data integrity: Constraints, foreign keys, and validation happen at the database level.
- Universally understood: SQL skills are widespread and documentation is abundant.
Weaknesses of relational databases:
- Rigid schema: Adding new attributes or relationships requires migrations that touch every existing record.
- Performance degrades with complex queries: As soon as your query needs to join across multiple tables, performance can drop dramatically.
- Not optimized for highly connected data: Modeling network topology with hundreds of device-to-device relationships becomes painful.
Relational databases are best for traditional applications requiring strict data integrity, transactional workloads where consistency is critical, and systems where the data model is relatively stable over time.
The relational database was never designed to make schema changes easy. It prioritizes scalability and integrity at the cost of flexibility.
2. Key-value store databases
Key-value stores take a completely different approach. Think of them as massive, distributed dictionaries where you store values and retrieve them by key. Examples of key-value store databases include Redis and Memcached.
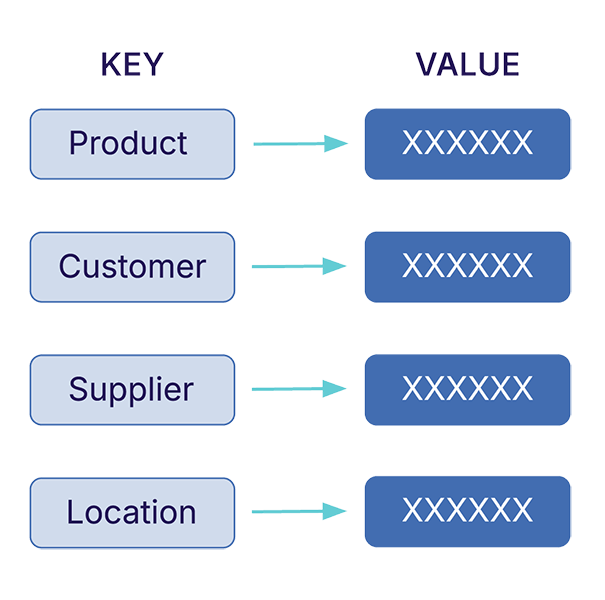
How they work: You have a key (like device:nyc-router-01) and a value (like a JSON blob with device info). That's it. No tables, no relationships, barely any query engine.
Strengths of key-value store databases:
- Extremely fast: They're optimized for speed above everything else.
- Simple to use: Basic key lookups are trivial.
- Great for caching: They're perfect for storing session data or frequently accessed information.
Weaknesses of key-value store databases:
- No schema enforcement: You can store anything as a value.
- Minimal query capabilities: You can look up a key, and that's about it.
- No relationships or data integrity: The database doesn't understand how your data relates to other data.
Key-value stores are best for caching layers, session storage, and real-time applications where speed is the only priority.
They are the ultimate trade-off. By eliminating schema enforcement, constraints, relationships, and complex queries, key-value stores achieve incredible performance but you sacrifice almost everything else.
3. Document store databases
Document stores like MongoDB and Elasticsearch sit somewhere between key-value stores and relational databases. They're optimized for storing and retrieving JSON-like documents.
How they work: Instead of rigid tables, you store flexible documents. Each document can have different fields. You might have a simple schema (often using JSON Schema), but it's not strictly enforced.
Strengths of document store databases:
- Flexible schema: Adding new fields is trivial.
- Good scalability: It's built for horizontal scaling across many servers.
- Faster than relational for some use cases: No JOINs are needed for nested data.
Weaknesses of document store databases:
- Limited data integrity enforcement: Consistency checking happens in your application code, not the database.
- Less powerful query capabilities: It doesn't match SQL's sophistication.
- Responsibility for consistency falls on you: The database won't stop you from creating inconsistent data.
Document store databases are best for content management systems, product catalogs, log aggregation, and scenarios where you need more structure than key-value but more flexibility than SQL.
Document stores focus on speed and scalability rather than data integrity. They give you more structure than key-value stores but less enforcement than relational databases.
4. Graph databases
Here's the database type that deserves far more attention than it gets, especially for network automation: the graph database. Examples include Neo4j and ArangoDB, with Neo4j being the most widely adopted.
The first time many engineers encounter a graph database, the reaction is often, "What the heck is this? Give me my Postgres back!" But after working with them, many fall in love with their capabilities. The natural modeling of relationships, and performance characteristics for connected data, are just so powerful .
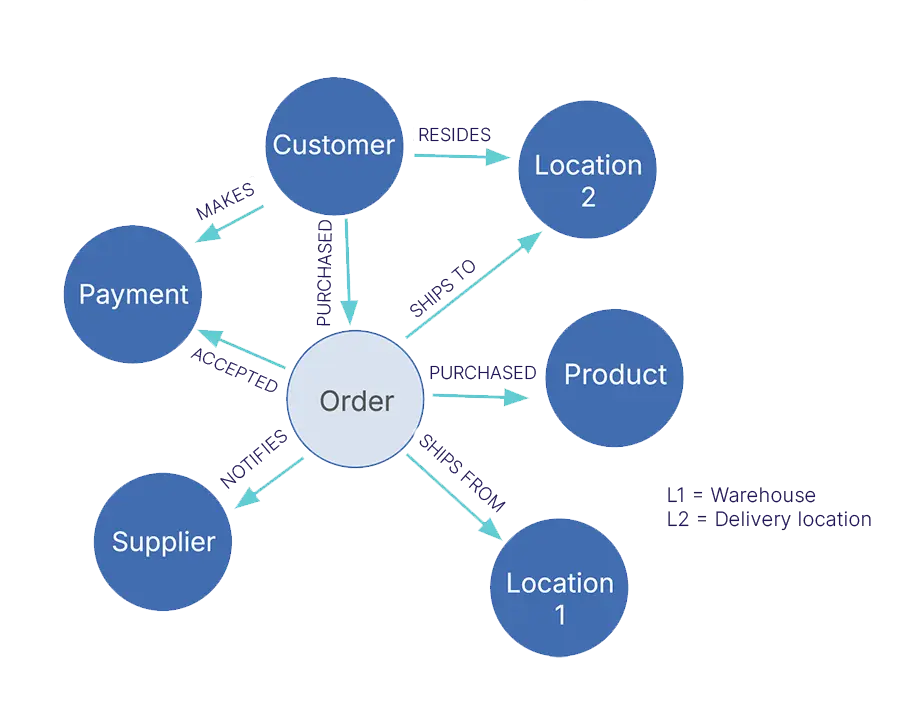
How they work: Instead of tables, graph databases store individual entities (called nodes) connected by relationships (called edges). There's no concept of a table that holds all devices. Instead, each device is its own node, connected through actual relationships to other nodes like interfaces, sites, and tags.
Relationships are first-class citizens in graph databases, not afterthoughts managed through foreign keys.
Strengths of graph databases:
- Excellent for highly relational data: Network topology is naturally a graph.
- Powerful query language: Cypher (Neo4j's language) and the newly standardized GQL provide sophisticated querying capabilities.
- Flexible schema: Schema is optional in Neo4j. You can add new node types and relationships without migrations.
- Linear performance as query depth increases: Unlike SQL where JOINs get exponentially slower, graph databases maintain performance as you traverse deeper relationships.
- Easy to add new relationships: No schema changes are required. Just create new edges.
- Perfect for network infrastructure modeling: The database structure matches the reality of how networks are structured.
Weaknesses of graph databases:
- Less familiar to most engineers: There's a smaller community and fewer resources for graph databases than for relational databases.
- Smaller ecosystem: There are fewer tools, libraries, and integrations than for relational databases.
- Learning curve: Query languages like Cypher require new mental models.
Graph databases are best for network source of truth systems, any domain with complex interconnected data, scenarios requiring flexible schema evolution, and applications where deep relationship traversal is common.
5. Time-series databases
The final major database category optimizes for a specific use case: timestamped data that accumulates over time. Examples of time-series databases include Prometheus and InfluxDB.
How they work: Time-series databases are built around data points with timestamps. They excel at storing metrics, performing aggregations, and running queries like "show me average interface utilization over the last 24 hours."
Strengths of time-series databases:
- Powerful aggregation queries: You can sum, average, and do percentile calculations across time windows.
- Optimized for time-based data: Storage and retrieval of metrics is efficient.
- Purpose-built features: They enable retention policies, downsampling, and other time-series specific capabilities.
Weaknesses of time-series databases:
- No schema enforcement: There's usually no formal schema at all.
- No relationships: They can't model how devices relate to sites or interfaces relate to devices.
- Purpose-built only: They're not suitable for general data storage.
Time-series databases are best for monitoring systems, telemetry collection, metrics storage, and any scenario where you're primarily collecting and analyzing timestamped data points.
They give you a very powerful query engine for aggregation, but they trade away schema and relationships entirely.
Note: Time-series databases should not be confused with temporal graphs, which add a timeline element to a graph database. In a temporal graph, every node and relationship in the graph database knows not only what it connects to, but when that connection was valid.
The connection between database and schema
Now that you understand the major database categories, let's explore how schemas and databases relate to each other.
Some schema languages are stateless, which means they're defined separately from any storage solution. Others are stateful, that is, they're coupled with a specific database system.

Stateless schema languages
JSON Schema, GraphQL, and YANG are stateless. They define data structure but don't dictate where or how you store data. This gives you maximum flexibility:
- You can validate data with JSON Schema but store it in MongoDB, PostgreSQL, or files.
- You can define a GraphQL API and back it with any database through resolvers.
- You can use YANG models with NETCONF but store actual data anywhere.
The trade-off: Since the schema isn't tied to storage, enforcement happens at the application level. Your code must validate data against the schema. The storage layer won't necessarily prevent schema violations.
Stateful schema languages
SQL and Infrahub couple the schema with the storage system. When you define a SQL schema with CREATE TABLE, you're directly configuring how the database stores data. The schema is mandatory and enforced at the database level.
The trade-off: Changes to the schema may require data migrations. If you add a new required column to a SQL table, every existing row must be updated. If you change how relationships work, you might need to restructure your data.
But you gain tighter integration and stronger enforcement. The database itself prevents schema violations.
Schema enforcement at the database layer is something we covered in our post on schema types. We talked about about the three levels where schemas can be defined and enforced:
- Storage level (stateful): Schema enforced by the database
- Application level (stateless): Schema enforced by your code
- User level (no formal schema): Schema exists only as documentation
For network automation in production, you want schema enforcement at either the storage or application level, not just in user documentation.
Considering query performance and depth
Database architecture makes a dramatic difference when it comes to how performance scales as queries get more complex.
Consider this query: "Show me all interfaces on devices located in the NYC datacenter that are connected to production VLANs."
This query traverses multiple relationships:
- Site → Device
- Device → Interface
- Interface → VLAN
- VLAN → (check production flag)
That's a depth of four hops through your data model.
The relational database challenge
In SQL, this query requires multiple JOINs:
SELECT interfaces.*
FROM sites
JOIN devices ON devices.site_id = sites.id
JOIN interfaces ON interfaces.device_id = devices.id
JOIN vlan_assignments ON vlan_assignments.interface_id = interfaces.id
JOIN vlans ON vlans.id = vlan_assignments.vlan_id
WHERE sites.name = 'NYC-DC1'
AND vlans.is_production = true;Each JOIN operation gets expensive. The database must match rows across tables, build intermediate result sets, and filter them. As you add more relationships to traverse, performance degrades exponentially.
For queries that touch a single table or perform simple JOINs, relational databases are excellent. All related data sits together in memory.
But network automation queries frequently traverse deep relationships. "Show me the path between these two devices" might touch 10+ node types.
The graph database advantage
Here's that same query we made in SQL but using Cypher in a graph database instead:
MATCH (site:Site {name: 'NYC-DC1'})<-[:LOCATED_IN]-(device:Device)
-[:HAS_INTERFACE]->(interface:Interface)
-[:ASSIGNED_TO]->(vlan:VLAN {is_production: true})
RETURN interface;Graph databases use pointer-based storage. Each node contains direct references to its connected nodes. Traversing a relationship is a single pointer lookup, not a JOIN operation. Performance scales linearly with query depth rather than exponentially.
When you're working with network topology—devices connected to interfaces, interfaces connected to cables, cables connected to patch panels, patch panels in racks, racks in rooms, rooms in buildings—those deep traversals are your daily reality. This is where graph databases shine.
How much faster?
To illustrate the difference in query speed between the two types of databases, Aleksa Vukotic performed an experiment with a data set of one million entries.
They built a query in both MySQL (relational database) and Neo4j (graph database) to traverse the connections between the data entries. The results show that as query depth rises, MySQL quickly bogs down. Execution time is in seconds for 1,000 data points.

The rise of graph databases
Despite their advantages for connected data, graph databases remain less popular than relational databases. That makes sense. Most applications don't need flexible schemas or deep relationship traversal.
The majority of software systems still use relational databases for good reasons: they're mature, well understood, provide strong integrity guarantees, and work great for traditional business applications.
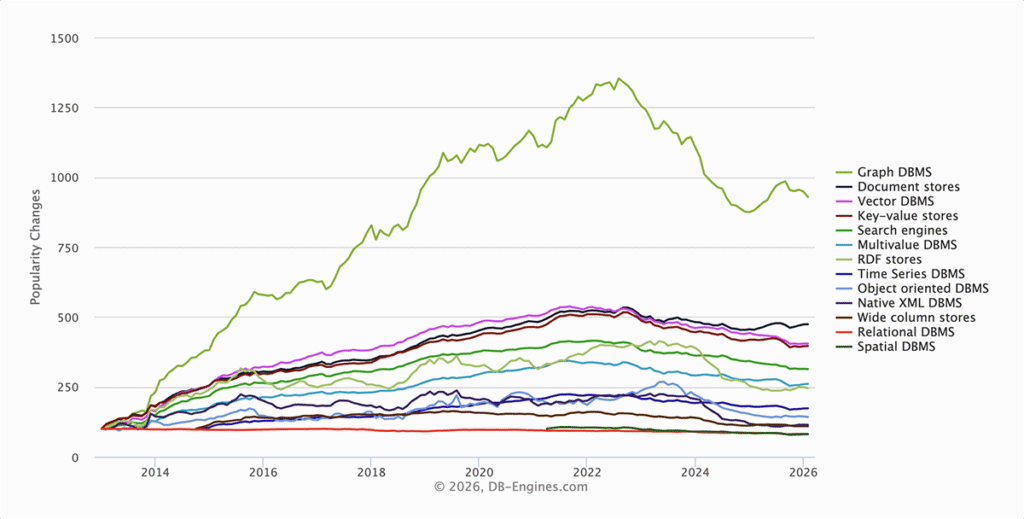
But growth trends tell an interesting story. Even though their adoption has dipped slightly since 2022, graph databases consistently show some of the highest growth rates compared to other categories. Alongside time-series databases, they're the database types seeing the most increasing interest.
The database you choose shapes what's possible
Performance characteristics, schema flexibility, and query capabilities all flow from the foundational decision of which database to use.
How does this matter in network automation? Simply put, traditional network source of truth tools struggle because they use the wrong database type.
Network infrastructure forms natural graph structures with constantly evolving schemas. Relational databases require risky, time-consuming migrations for schema changes, and their JOIN-based queries degrade exponentially as relationship depth increases.
Graph databases were designed to support exactly the things automation needs: flexible schemas, efficient relationship traversal, and linear performance characteristics for deeply connected data.
Next steps
If you're ready to see how graph databases can transform your network automation workflows, here's how to get started with Infrahub:
- Try the sandbox: Experiment with Infrahub's graph-based approach and see how it handles complex network relationships in the Infrahub sandbox.
- Join the community: Connect with other network automation engineers and Infrahub users on Discord to discuss database strategies and get implementation guidance
- Request a personalized demo: Talk with the OpsMill team about your specific infrastructure data challenges and see how a graph database approach could work for your environment.
