
Infrahub provides multiple ways to interact with your infrastructure data, including the web GUI, GraphQL queries, and the Python SDK. These can be used to query, modify, create, or delete data in Infrahub. In this post, we’ll focus on using the Python SDK to query data from Infrahub.
This post assumes you're familiar with basic Python and Infrahub. If you’re new to these topics, don’t worry, you can still follow along.
Throughout this post, we’ll be using the Infrahub sandbox, which is available for anyone to access. The sandbox already has some data in it, so if you’d like to follow along or try this yourself, you can use it without needing to set up anything.
Introduction
The Python SDK supports both synchronous and asynchronous Python. However, in this post, we’ll focus on using synchronous Python, which I hope most of us are comfortable with. We’ll cover async in a future blog post.
Interacting with Infrahub through the Python SDK is done using a client object, which defines the Infrahub instance you’ll be working with. This client acts as the connection point, allowing you to query, create, modify and delete resources within Infrahub.
You can install the Infrahub Python SDK with the pip package installer. It’s always a good idea to use a virtual environment to keep dependencies isolated.
python3 -m venv venv
source venv/bin/activate
pip install infrahub-sdkThe InfrahubClientSync class provides the synchronous version of the Infrahub client. This is what we’ll use to interact with Infrahub in this post.
from infrahub_sdk import InfrahubClientSync
client = InfrahubClientSync(address="https://sandbox.infrahub.app")To instantiate a client object, we pass the Infrahub server address. For authentication, you can use the environment variable INFRAHUB_API_TOKEN to pass the API key. The API key can be created in the Infrahub GUI by navigating to Account Settings > Tokens. Once generated, you can set the environment variable as shown below.
export INFRAHUB_API_TOKEN="TOKEN_HERE"Please note that if you’re only querying data from the Infrahub sandbox, you don’t need an API token. However, if you’re modifying, creating, or deleting resources, authentication is required, and you’ll need to provide a valid API token.
We can also instantiate a client using the Config object. Instead of passing the server address directly to InfrahubClientSync, we create a Config object and pass it to the client object. The API token can also be provided as part of the Config object using the api_token parameter.
from infrahub_sdk import InfrahubClientSync, Config
config = Config(
address="https://sandbox.infrahub.app",
api_token="182687c6-9445-8f39-dcb7-10658e5cfa49",
)
client = InfrahubClientSync(config=config)Similarly, authentication can also be done using a username and password, as shown below.
config = Config(username="admin", password="infrahub")Please note that for the purpose of this post, we are adding the credentials directly in the script, but in production, you should never hardcode API tokens or passwords in plain text.
Querying data
Now that we know how to create a client object and authenticate, let’s move on to querying data from Infrahub. In the sandbox, you will find devices, interfaces, VLANs, BGP peers, and more. Since most of us are familiar with VLANs, let’s start by querying the list of VLANs in Infrahub.
We can query data in three ways using the SDK.
- Querying all the nodes of a given kind, using the
allmethod - Querying a single node of a given kind, based on some filters, using the
getmethod - Querying multiple nodes of a given kind, based on some filters, using the
filtersmethod
You can view all VLANs in the Infrahub by navigating to Network Configuration > VLAN. As shown in the screenshot, each site has two VLANs, and there are a total of five sites. Now, let’s see how we can retrieve the list of VLANs using the Python SDK.
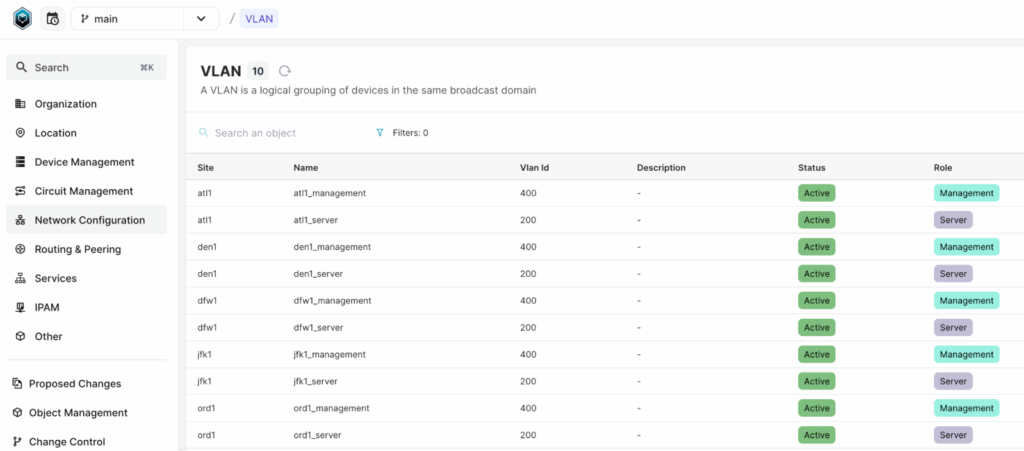
Please note that the sandbox may change over time, so VLANs may appear under a different menu with a different schema. Please keep this in mind if you don’t see them in the exact location mentioned in this post.
Querying all nodes
Let’s start by querying all the VLANs. This can be done by calling the all() method on the client object and passing the kind of the resource as an argument. You can find the ‘kind’ of a resource by inspecting the schema.
To view the schema, you can click the ? icon at the top right of the page, then select Schema from the dropdown menu. This will open the schema explorer. In the schema, we can also see other Properties, Attributes, and Relationships, which we’ll cover later in this post.
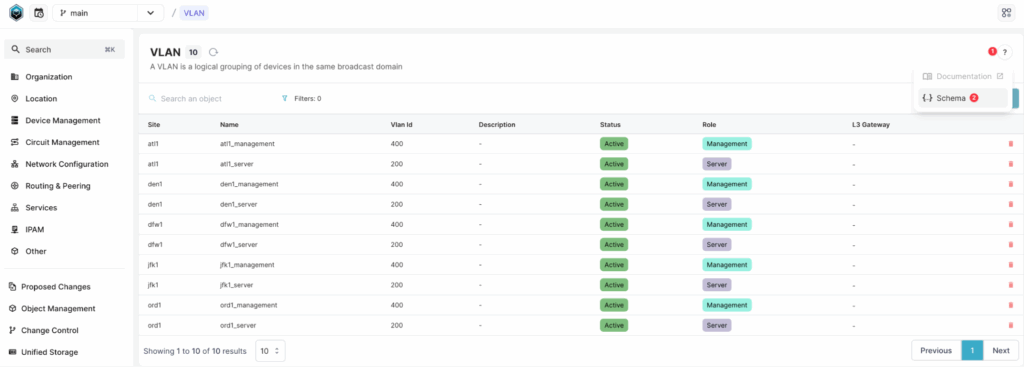
To query all VLANs, we can use the following script.
from infrahub_sdk import InfrahubClientSync, Config
config = Config(
address="https://sandbox.infrahub.app",
api_token="182687c6-9445-8f39-dcb7-10658e5cfa49",
)
client = InfrahubClientSync(config=config)
all_vlans = client.all("InfraVLAN")
for vlan in all_vlans:
print(f"VLAN ID: {vlan.vlan_id.value}, Name: {vlan.name.value}")The script initializes a connection to the Infrahub Sandbox using the InfrahubClientSync class as usual. We then use the all() method to retrieve all VLANs by specifying “InfraVLAN”, which is the kind associated with VLANs in the schema. The script then loops through the returned list of VLAN objects and prints their vlan_id and name attribute values.
If we check type(all_vlans[0]), we get infrahub_sdk.node.InfraVLANInfrahubNodeSync. This means the returned objects are Python objects constructed from the schema. In this case, each VLAN returned from the query is an instance of the InfraVLANInfrahubNodeSync class.
Querying a single node
In the previous example, we used the all() method to query all nodes of the same kind. Now, let’s see how we can query a single node of a kind. Using the same VLAN example, let’s try to query the VLAN named atl1_server.
To retrieve a single node, we use the get() method. The first argument is still the kind, but we also need to pass one or more filters to specify which node we want.
What are filters?
Filters allow us to search for specific attributes of a node as well as its relationships. For every attribute and relationship in a schema, a set of filters is automatically generated, allowing us to refine queries based on both attributes and related objects.
For every attribute in a schema, the following filters are automatically generated.
- ids: (list) Filters for a list of node ids
- hfid: Human-friendly Identifier of the specific node
- attribute__value: Filters for a single attribute value.
- attribute__values: (list) Filters for multiple attribute values.
- attribute__is_visible: (boolean) Filters for whether an attribute is visible.
- attribute__is_protected: (boolean) Filters for whether an attribute is protected.
- attribute__source__id: Filters for the source property of an attribute.
- attribute__owner__id: Filters for the owner property of an attribute.
- attribute__isnull: (boolean) Filters for attributes that have a null (empty) value.
For relationships, the following filters are generated.
- relationship__attribute__value
- relationship__attribute__values
- relationship__attribute__is_visible
- relationship__attribute__is_protected
- relationship__attribute__source__id
- relationship__attribute__owner__id
- relationship__ids
- relationship__isnull
To explain this, if a node has an attribute such as name, the corresponding filter would be name__value, where the word “attribute” in the filter format is replaced with the actual attribute name. Similarly, if you want to find nodes that do not have a description, you can use the filter description__isnull to retrieve only those with an empty value. (Assuming the node has an attribute called description)
Similarly, an InfraDevice has a relationship to platform, so if you want to filter devices based on the platform name, the filter would be platform__name__value. This follows the same pattern, where the relationship name is used in place of “relationship”, allowing you to query nodes based on their related objects.
You can also find the available filters for any given kind in the GraphQL Sandbox by opening the explorer, navigating to the kind, and expanding it.
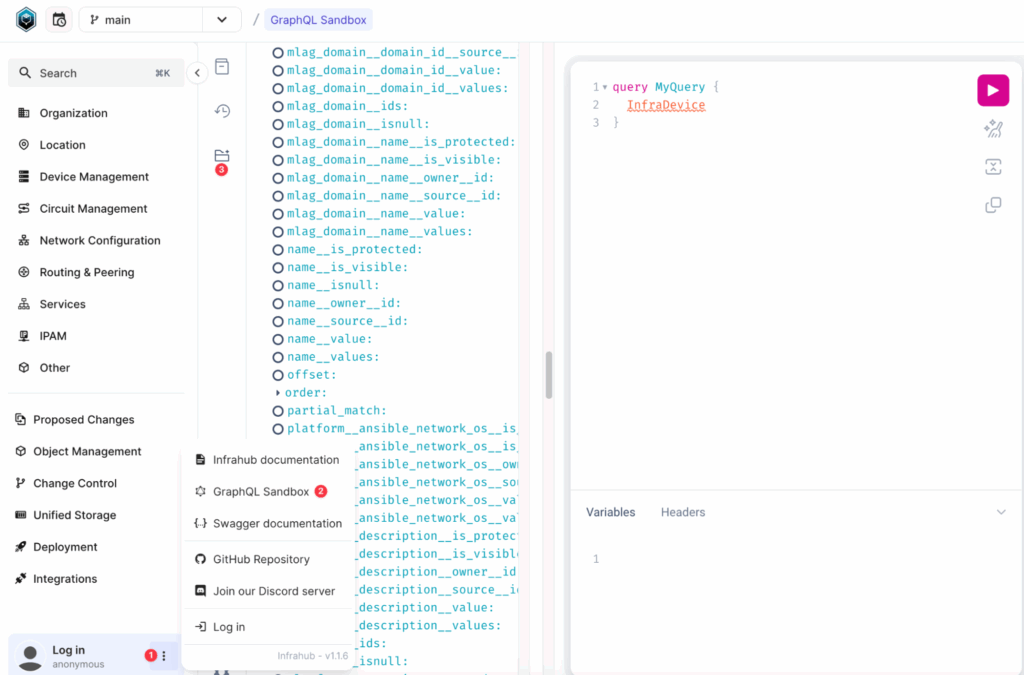
For the InfraVLAN kind, we can inspect the schema to see the available attributes.
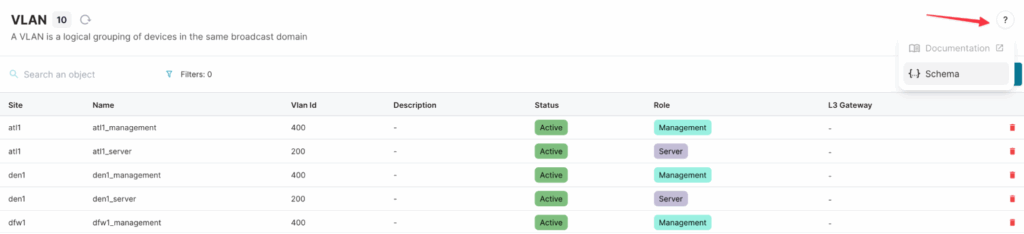
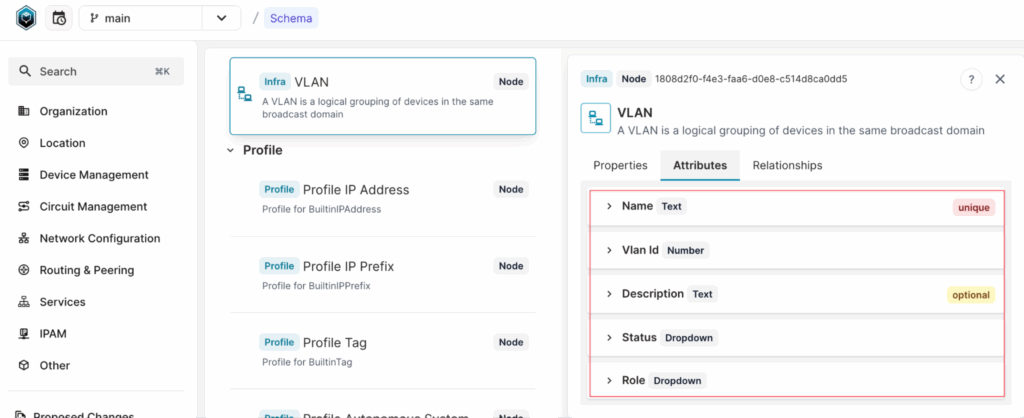
As shown in the schema, InfraVLAN has attributes such as name, VLAN ID, description, status, and role. If we want to query a VLAN by name, we use the name__value filter.
Here’s how we can retrieve the VLAN named atl1_server.
vlan = client.get("InfraVLAN", name__value='atl1_server')
vlan.vlan_id.value # Output: 200This retrieves the VLAN and allows us to access its attributes, such as the VLAN ID.
We can also use multiple filters by specifying multiple attributes in a query. For example, we can refine our VLAN search by filtering based on more than one attribute. This might not be necessary in this specific case since we can already query the VLAN using its name, but it’s useful to understand how filtering works with multiple conditions. Here’s an example where we query a VLAN using name, VLAN ID, and role.
vlan = client.get(
"InfraVLAN", name__value="atl1_server", vlan_id__value=200, role__value="server"
)You might have noticed that we use the term “query a single node of a kind.” But what does that mean? What happens if the query returns multiple nodes instead of just one?
We can easily test this by using the vlan_id attribute as a filter. Since we know there are multiple VLANs with VLAN ID 200 (even though they belong to different sites), let’s try to query it.
vlan = client.get("InfraVLAN", vlan_id__value=200)Here, we are trying to retrieve a VLAN with vlan_id = 200, but when we run the script, we get the following error.
IndexError: More than 1 node returnedThis confirms that the get() method expects to return only one node, but since multiple nodes match the query, it fails.
Querying multiple nodes
You can query Infrahub for multiple nodes of a particular kind by using the filters() method and using 1 or more filters. Previously, we saw that the get() method is limited to querying a single node and returns an error if multiple nodes match the filter. To query multiple nodes, we can use the filters() method.
vlans = client.filters("InfraVLAN", role__value="server")
for vlan in vlans:
print(vlan.name.value, vlan.vlan_id.value)atl1_server 200
den1_server 200
dfw1_server 200
jfk1_server 200
ord1_server 200In this example, we query all VLANs where the role is “server”. Unlike get(), which returns a single object, filters() returns a list of matching nodes. We then loop through the results and print the name and VLAN ID of each VLAN.
Similarly, we can use a relationship filter to find VLANs based on their associated Site. Since Site is a relationship of InfraVLAN, as seen in the schema, we can apply a filter to retrieve all VLANs within a specific site.
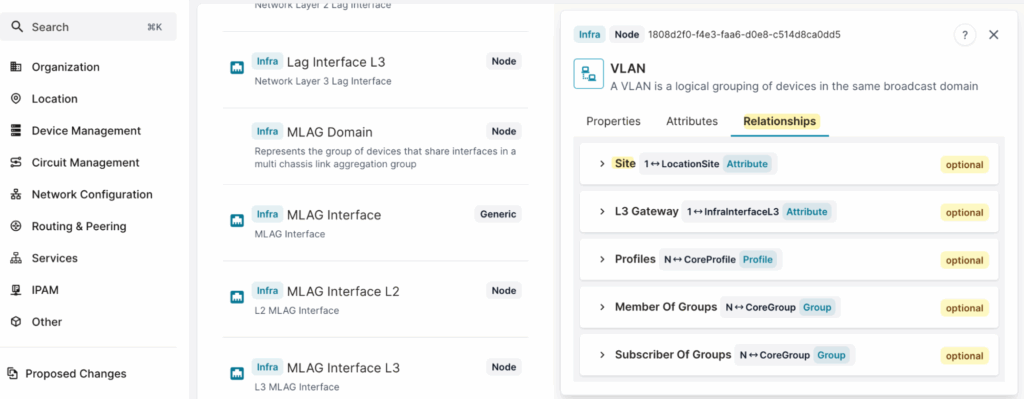
For example, if we want to find all VLANs in atl1, we can use the following query.
vlans = client.filters("InfraVLAN", site__name__value="atl1")
for vlan in vlans:
print(vlan.name.value, vlan.vlan_id.value)#output
atl1_management 400
atl1_server 200Attributes and relationships
In this final section, let’s look at how the Infrahub SDK fetches the attributes and relationships associated with a node. So far, we have focused on querying VLANs, but now let’s switch to querying devices as an example.
devices = client.filters(
"InfraDevice", type__value="7280R3", status__value="provisioning"
)
for device in devices:
print(device.name.value)#output
den1-edge1In the script, we are querying for nodes of kind “InfraDevice” that match specific filters:
- type = “7280R3”
- status = “provisioning”
From the web GUI, we can see that only one device matches these criteria – den1-edge1. Running the script confirms this, as the output returns only that device.
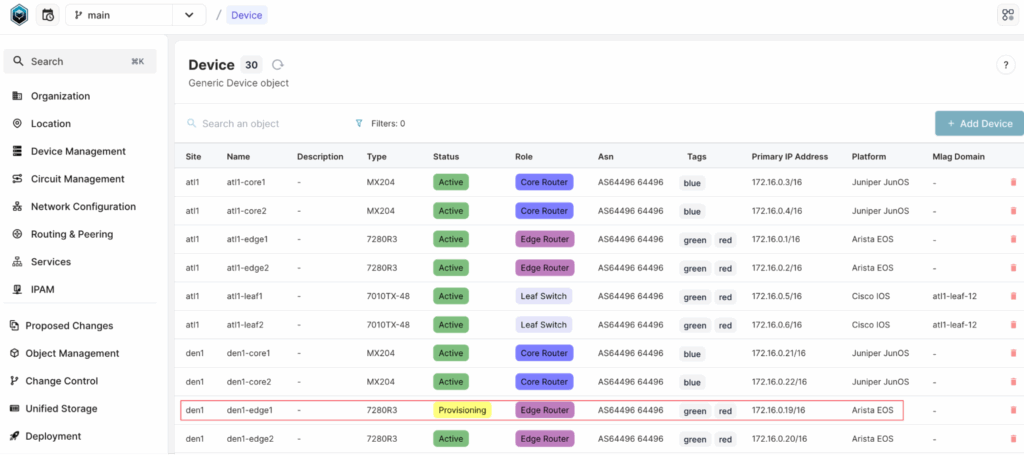
We can also print the name attribute of the device. Similarly, we can access other attributes, such as status and role. These attributes are defined in the schema for this specific kind, and you can view them in the web GUI under the Schema section.
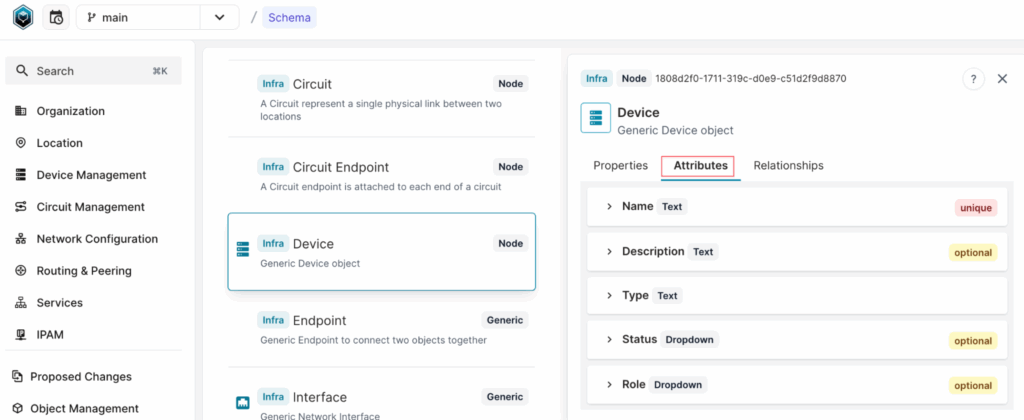
If we open this device in the web GUI, we can also see other information such as platform, primary IP address, and interfaces. The question now is, can we access this information when querying the device through the SDK?
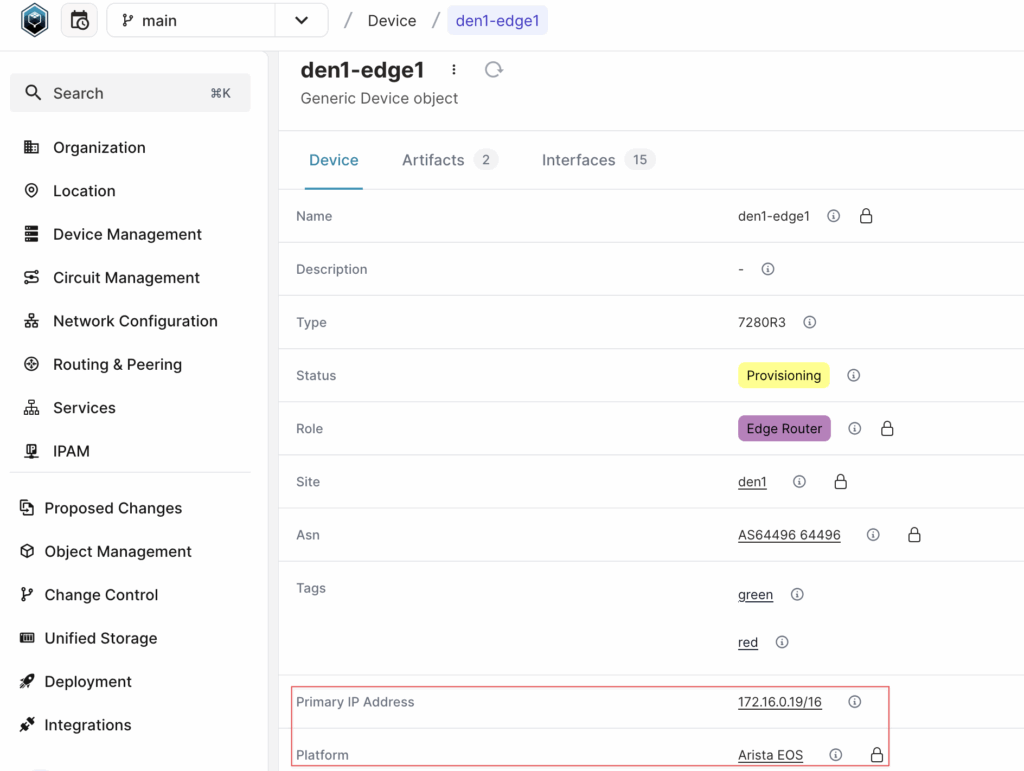
By default, the result of a query will include:
- Attributes
- Relationships of cardinality one
- Relationships of kind Attribute or Parent
Relationships that are included in a query will be automatically initialized with some information such as id, hfid or display_label. But the related node itself will not be included. So, let’s explore this in detail with a few examples.
If we test this by running the following query, it will return the display_label of the platform, so the output will be “Arista EOS”.
device = client.get("InfraDevice", name__value="den1-edge1")
device.platform.display_label#output
Arista EOSUsing the fetch() method
However, if you want to access the platform’s attributes, which were not fetched as part of the query, you need to fetch them explicitly.
device = client.get("InfraDevice", name__value="den1-edge1")
device.platform.fetch()
device.platform.peer.napalm_driver.value#output
eos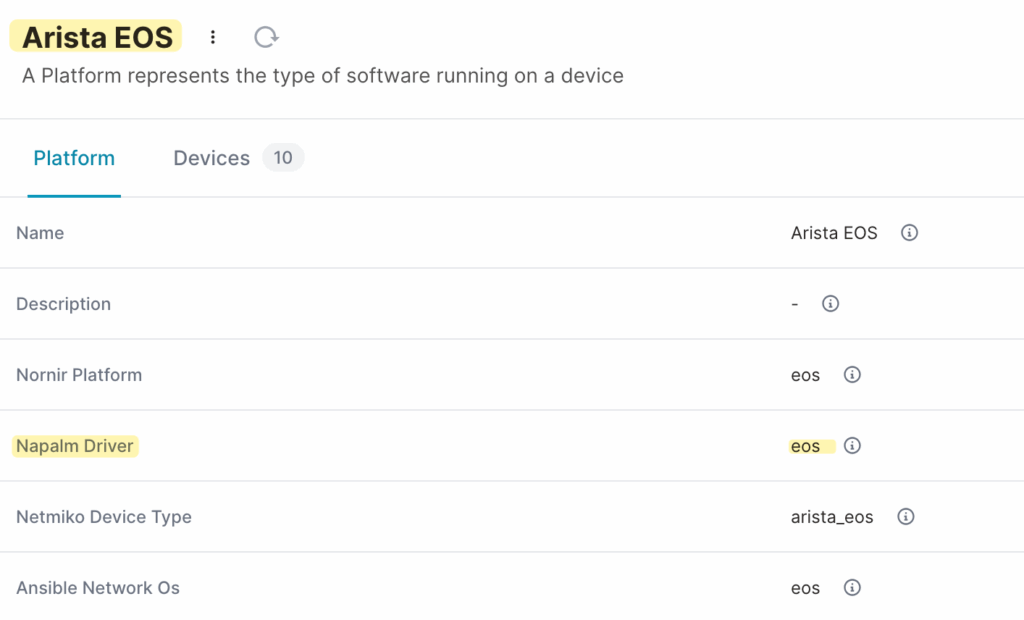
One important thing to note here is that device.platform does not refer to the platform itself but rather represents the relationship between the device and its platform. If you want to access the actual platform node and its attributes, you need to use the peer property.
device = client.get("InfraDevice", name__value="den1-edge1")
device.primary_address.fetch()
device.primary_address.peer.address.valueFetching more relationships
In the previous section, we looked into fetching relationships of cardinality one and relationships of kind Attribute or Parent, but what about other relationships like interfaces, which have a cardinality of many and are of kind components?
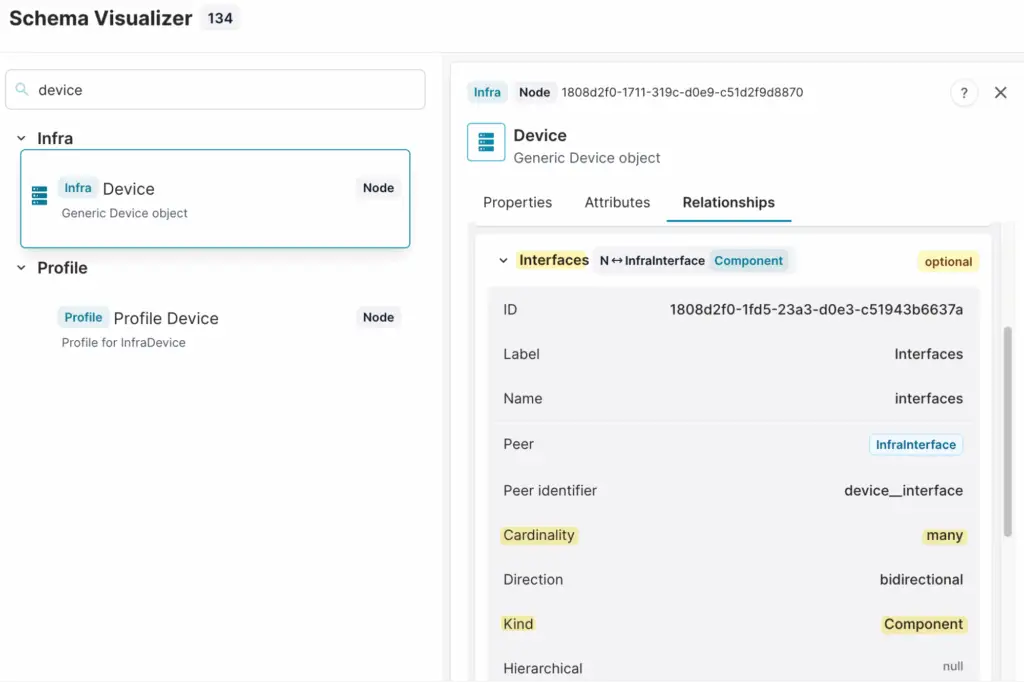
Interfaces, for example, are not included in the query by default, but we can use the include argument to fetch the interfaces relationship.
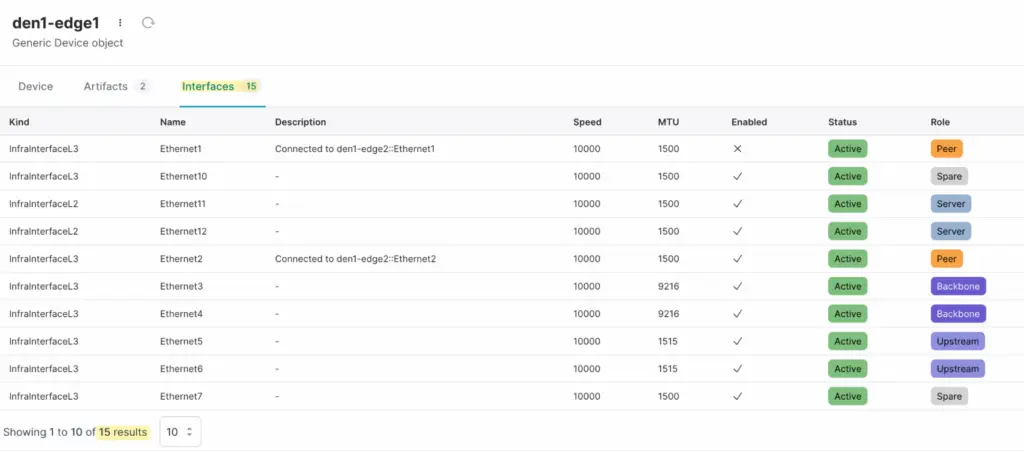
To retrieve these interfaces, we need to add the interfaces relationship to the include argument when querying the device.
device = client.get("InfraDevice", name__value="den1-edge1", include=['interfaces'])
device.interfaces.fetch()
for interface in device.interfaces.peers:
print(f"{interface.peer.name.value} - {interface.peer.role.value}")#output
Ethernet1 - peer
Ethernet10 - spare
Ethernet11 - server
Ethernet12 - server
Ethernet2 - peer
Ethernet3 - backbone
Ethernet4 - backbone
Ethernet5 - upstream
Ethernet6 - upstream
Ethernet7 - spare
Ethernet8 - spare
Ethernet9 - peering
Loopback0 - loopback
Management0 - management
port-channel1 - serverprefetch_relationships
You can also use prefetch_relationships to fetch related nodes automatically when querying a device. This eliminates the need to use the fetch() method later, as the relationships are retrieved upfront. However, keep in mind that depending on what you are querying, this can result in a large amount of data being returned. When using fetch(), you have full control over which relationships are retrieved and when, allowing for more efficient queries when dealing with large datasets.
device = client.get(
"InfraDevice",
name__value="den1-edge1",
prefetch_relationships=True,
populate_store=True,
)
print(device.platform.peer.name.value)
print(device.primary_address.peer.address.value)#output
Arista EOS
172.16.0.19/16Closing up
In this post, we explored how to query data from Infrahub using the Python SDK, covering single and multiple node queries, filtering, and retrieving related objects using fetch() and prefetch_relationships. We also looked at how relationships of different cardinalities affect query results. If you’re following along with the Infrahub sandbox, try running some queries yourself and feel free to reach out if you have any questions. You can find us on the OpsMill Discord server.
