 Announcing Infrahub 1.0!!
Announcing Infrahub 1.0!!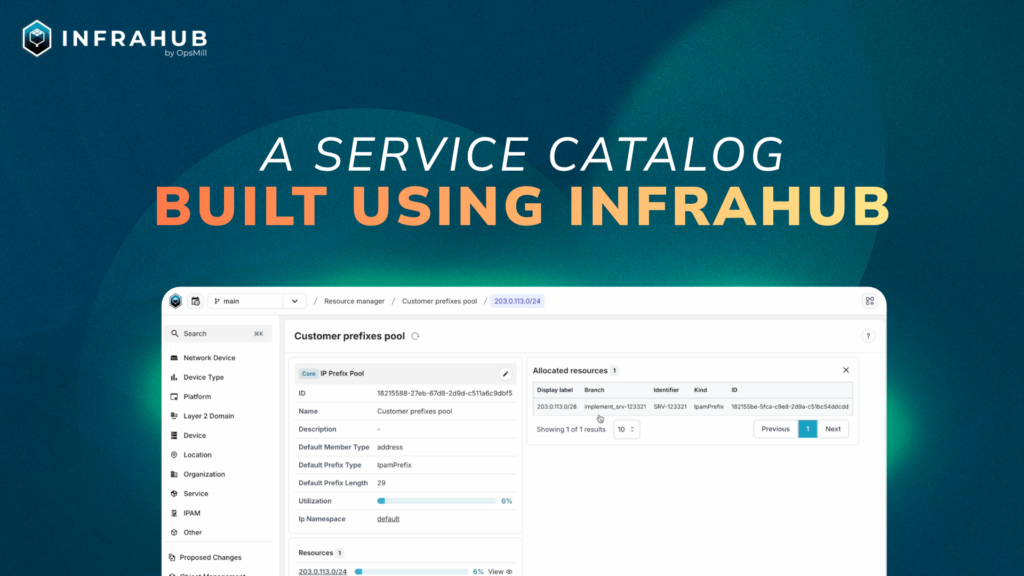



During the schema development process, it’s helpful to use infrahubctl to check and load the schema in a branch, making adjustments as needed. In a production context, we will leverage Infrahub’s Git integration to load the schema in a controlled manner.


We now have the data model and data to support our business. It captures everything from services to the backbone, with some abstraction for flexibility. This setup is a strong foundation for automation.
… then capture the business logic …
Let’s now look at how to codify the business rules for service provisioning using Infrahub’s generator feature. To put it simply, a generator is a Python script that interacts with data to transform a high-level service request into a technical implementation. The process starts with defining inputs and mapping them to the final output.

Generators are built on the concept of idempotency. If you are familiar with Ansible, this concept should sound familiar. The goal is to make the generator repeatable: it assigns resources the first time it runs, and if run again, it changes nothing if the desired state is already achieved. This approach ensures the code is robust and predictable.
Another convenient feature is Infrahub’s Resource Manager. It allows users to create pools and allocate resources from them, such as prefixes, IP addresses, or even numbers. We will use this feature to allocate our prefixes in a branch-agnostic and idempotent way. Additionally, we’ll use a number pool for VLAN IDs. This can seamlessly integrate with the generator.


The application will have two main pages: the form and the list of requests. The form provides a streamlined interface with only the relevant inputs, allowing users to request a new service in a controlled manner. It creates a “request” (a proposed change in Infrahub), which can be monitored on the second page. A network architect will review the request in Infrahub and approve it. Once approved, service delivery teams can view the allocated resources on the page and communicate them to the customer.


This form separates design from implementation. Users can request and interact with resources without dealing with low-level complexity. Additionally, we leverage Infrahub’s branching capabilities to push all changes to a dedicated branch, enabling architects to review exact modifications. Finally, the proposed change provides a runtime for the generator and offers future possibilities, such as user-defined checks and artifacts for device configuration.

Conclusion
The flexible schema feature of Infrahub is an ideal solution for capturing the service layer as closely to the data as possible. It enables you to represent every building block of your current services while also scaling to accommodate the growth of your business, such as the addition of new products. Additionally, the generator feature provides a robust mechanism to codify your business rules, transforming service requests into proper implementations in an efficient manner. Finally, encapsulating this logic into a form allows users to interact with data and resources more effectively, ensuring a clear separation of concerns.
Implementing this example as a production-ready product would require careful consideration of the overall BSS process. For instance, service objects likely exist prior to implementation (in a CRM system, for example) and would need to be synchronized with Infrahub. While creating a form is one option, it’s also possible that a system already present in your IT landscape (such as ticketing or CRM software) could fulfill this interface role.
Flexibility in the data model is crucial when it comes to the service layer. Since every organization operates slightly differently, there is no one-size-fits-all solution. Your source of truth must adapt to your business, capturing existing and future products as well as all their various building blocks. The quality of the data model, combined with the ease of interacting with the data it contains, will have a profound impact on downstream processes like service automation and resource management. Aligning a tailored data model, robust automation, and an efficient user interface will transform your source of truth into a powerful service factory.
![65a656b0aa32b71080018ef5_logoOpsmill[1]](https://www.opsmill.com/wp-content/uploads/2024/07/65a656b0aa32b71080018ef5_logoOpsmill1.svg "65a656b0aa32b71080018ef5_logoOpsmill[1]")